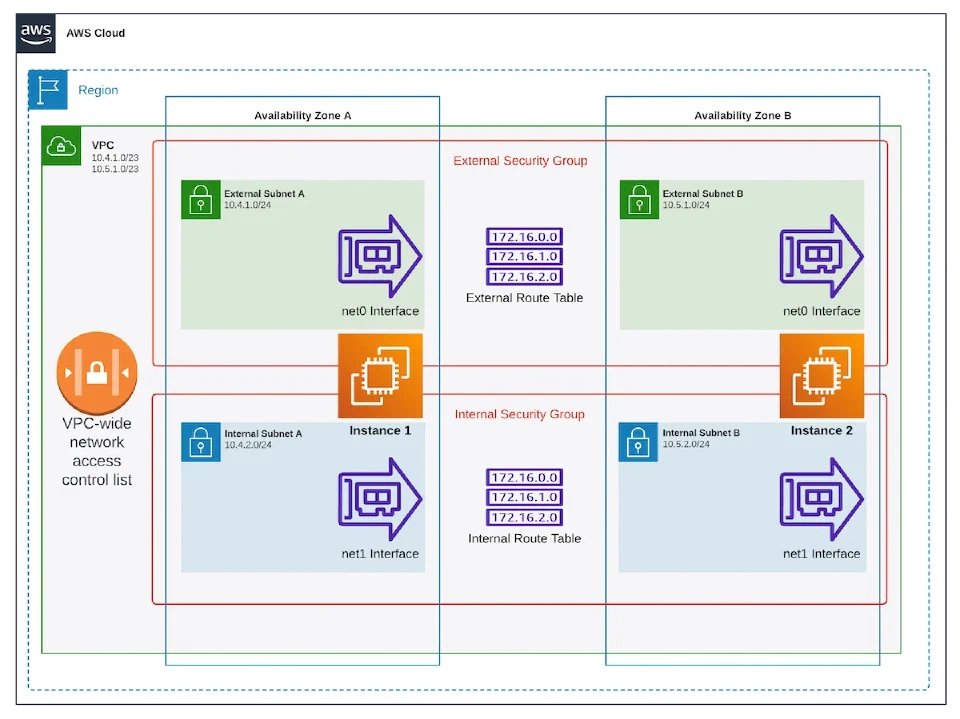
This morning at work I was presented with an interesting question: why can’t two instances in AWS seem to talk to each other on their internal / private network interfaces? To answer this, let’s back up a second and let me show you what the architecture of the environment is. First, take a moment and look at the diagram below and observe not only how many layers there are, but also that this is a pretty simple setup with one VPC containing two instances that are spread across two Availability Zones:
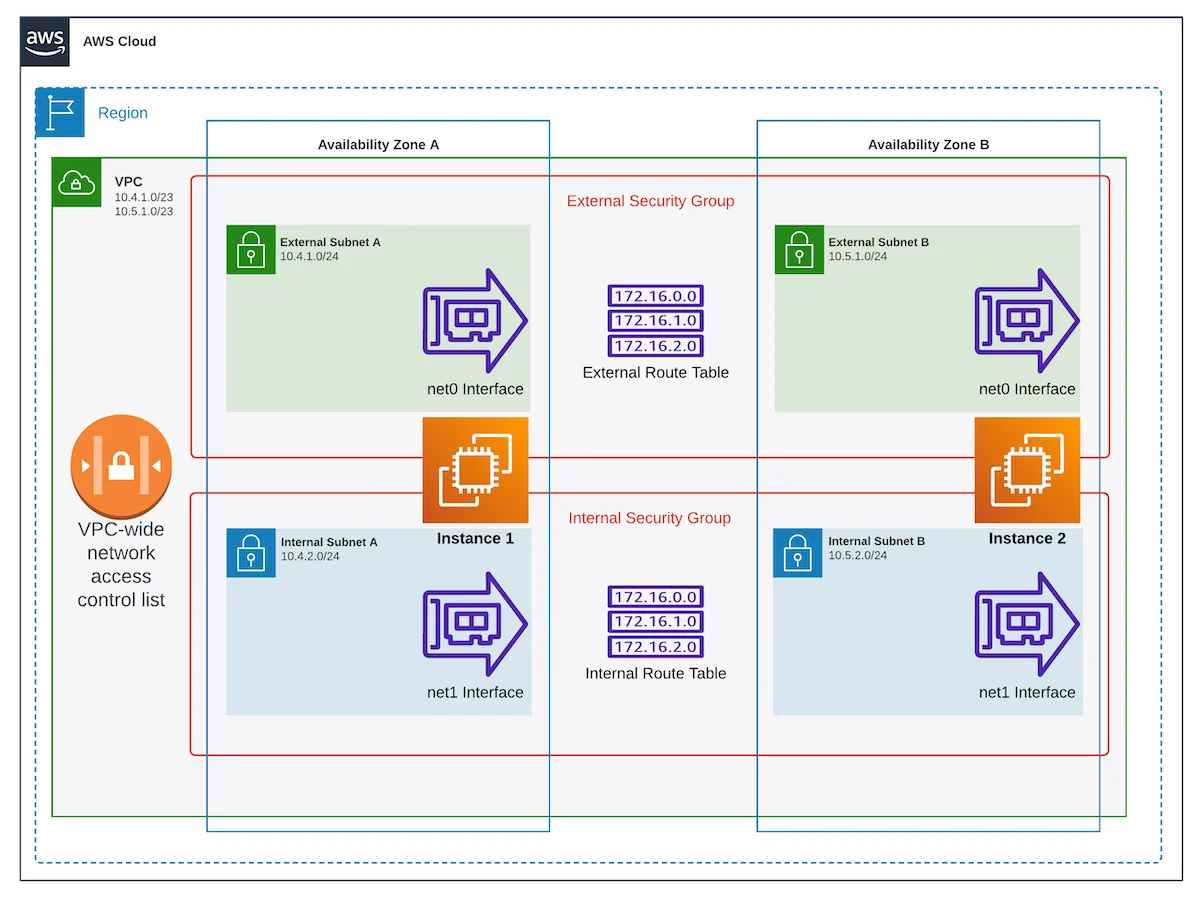
The question I was presented with is in reference to the “net1” interfaces in the diagram. After checking that there were no Network ACLs or Security Group rules preventing the communications, and ensuring that the Internal Route Table contained the two internal /24 subnets, it became clear that the problem was somewhere on the operating system configuration side of things. Time for side-by-side terminal sessions ssh’ed into each instance.
Out of habit, I first checked that there were no iptables rules preventing pings on the internal interfaces and found an explicit allow for icmp, so that wasn’t the issue. Next, I checked the output of ip route and saw there was no route to the other subnet… base-level problem found! Now to figure out what to do about it. First, I tried adding a rule based on the network interface: ip route add 10.5.2.0/24 dev net1 on Instance 1 & ip route add 10.4.2.0/24 dev net1 on Instance 2. Not surprisingly that didn’t work. At this point, I knew I was forgetting something simple diagnostic wise, but I couldn’t put my finger on it. Fortunately, one of my teammates mentioned tcpdump and that jarred my memory.
With the manual routes still in place, I fired up tcpdump -i net0 on Instance 2 and then tried pinging from Instance 1 both with ping -c3 10.5.2.10 and ping -I net1 -c3 10.5.2.10… nothing was received. As I was relaying this to my team I saw something interesting pop up in the tcpdump output:
$ sudo tcpdump -i net1
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on net1, link-type EN10MB (Ethernet), capture size 262144 bytes
09:41:43.433307 ARP, Request who-has 10.5.2.10 tell 10.5.25.1, length 28
09:41:43.433322 ARP, Reply 10.5.2.10 is-at 06:4f:8d:b9:b9:e3 (oui Unknown), length 28
This made me realize that Amazon uses the .1 address as the gateway in each subnet! With this new-found knowledge, I deleted the routes I had previously added and replaced them with these: ip route add 10.5.2.0/24 via 10.4.2.1 on Instance 1 & ip route add 10.4.2.0 via 10.5.2.1 on Instance 2. Put another way, ip route add <subnet in other AZ> via <.1 in the locally attached subnet>. BOOM! Everything works now… and the fix turned out to be a simple one that, in hindsight, should have been obvious. To make the new routes persistent, I added them into the Puppet code that manages each instance.
And that’s it. The key here was discovering that the .1 is the gateway and adding a simple route.
Edit 2024-06-03: Another coworker pointed me to https://docs.aws.amazon.com/vpc/latest/userguide/subnet-sizing.html which actually documentes this along with the reserved adderess for DNS on each subnet (.2 on a /24). Like so many things, this is easy if you know where to look…

 Nostr
Nostr